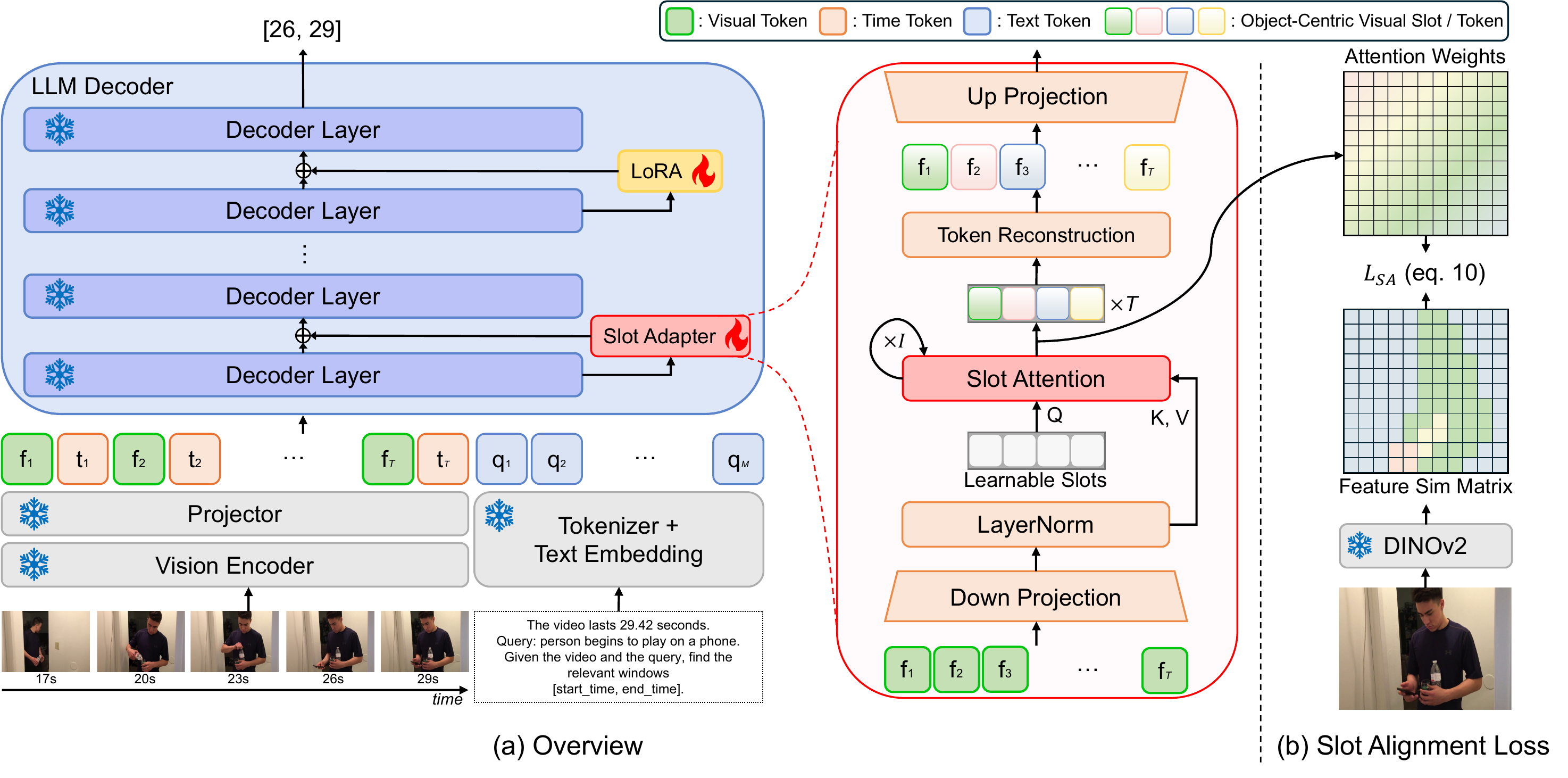
The Problem
Fine-tuned MLLMs don't see — they memorize.
A naïvely fine-tuned Qwen2.5-VL-3B drops 31% off-domain. Four diagnostics tell us why — and why object-centric decomposition fixes it.
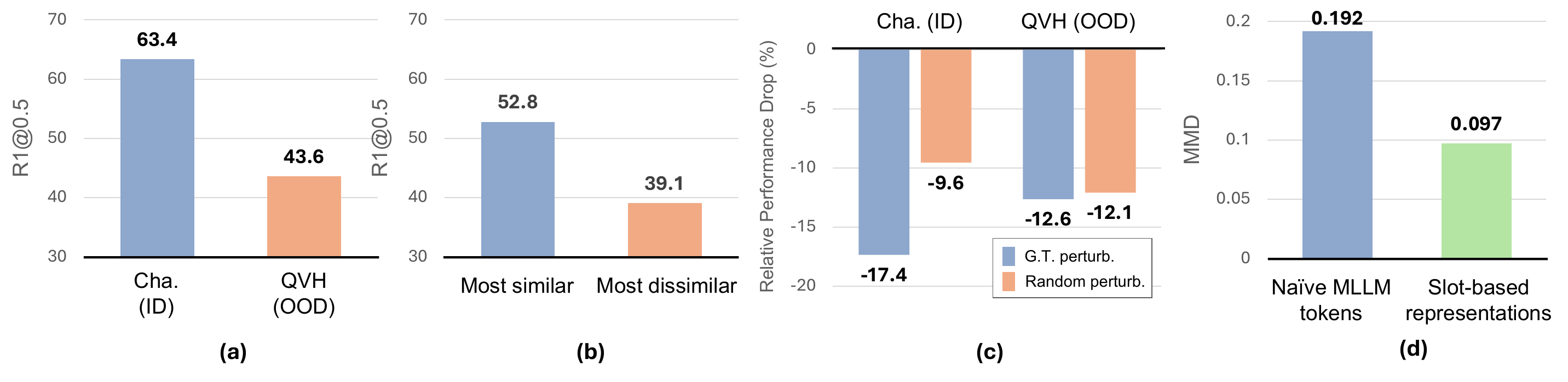
OOD performance drops 31%.
R1@0.5 on Cha. → QVH falls 63.4 → 43.6.
The drop tracks visual distance.
Most-similar OOD: 52.8; most-dissimilar: 39.1.
The model stops looking.
On OOD, perturbing the GT segment vs. a random one yields nearly the same drop (gap = 0.5%p).
Slots shrink the gap by 49.6%.
Source–target MMD: 0.192 → 0.097.